联邦学习
联邦学习:数据分散及隐私保护式分布式机器学习(翻译)
原文:Federated learning: distributed machine learning with data locality and privacy
联邦学习可以在不直接访问训练数据的情况下构建机器学习系统。数据保留在原始位置,这有助于保护隐私并降低通信成本。
- 在Cloudera VISION博客上了解联邦学习的业务和产品方面
- 探索我们的交互式联邦学习Demo,Turbofan Tycoon
联邦学习设定
联邦学习设定有两个方面。
首先,训练数据不能远离其来源。这种约束的原因可能包括隐私问题(我不想分享我宝贝的照片),监管障碍(HIPAA,GDPR等)和实际工程限制(网络连接昂贵,速度慢或不可靠,或数据量太大了)。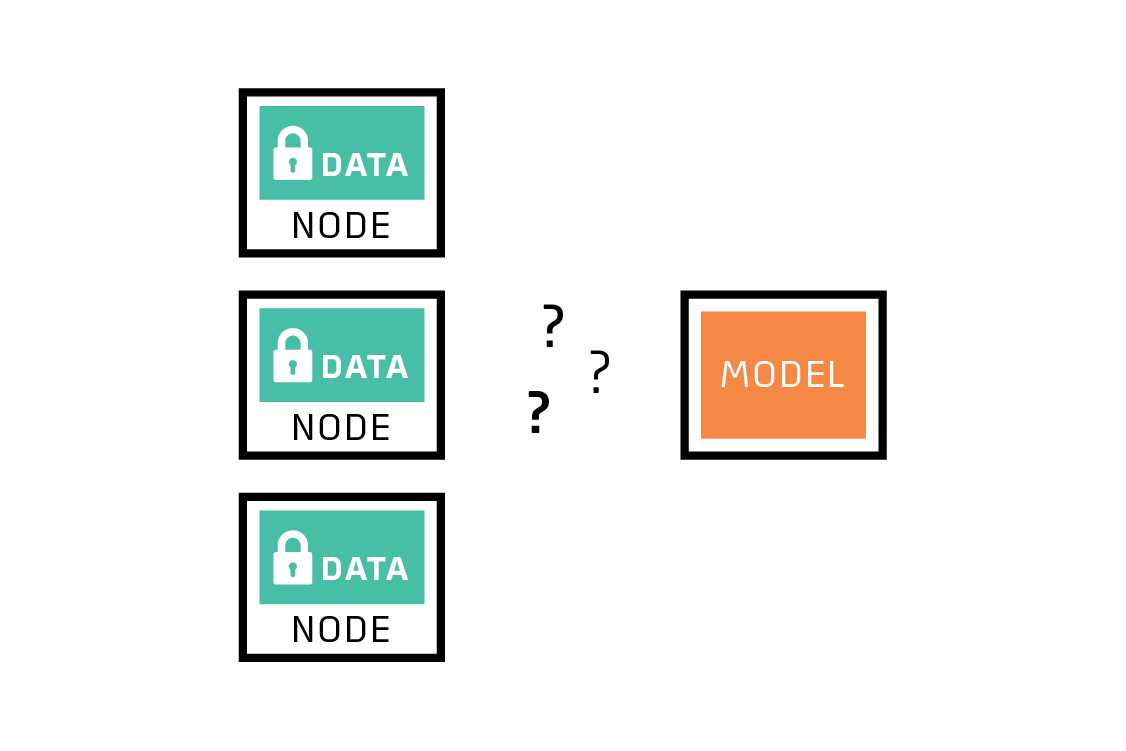
联邦学习有助于无法收集数据的情况。
有时,我们可以使用近似于实际数据行为的“代理”数据来解决此数据局部性约束。但几乎按照定义,代理数据并不像真实的那样好。例如,如果您想为智能手机训练语言模型,那么最好使用智能手机上的语言进行训练,例如,维基百科语料库。
其次,在联邦学习设定中,潜在训练数据源原则上可以彼此不同。换句话说,每个源上的数据分布都是no-IID,并且每个源的数据量可能非常不同。
联合平均
“联邦学习”是指一系列算法,其试图在上述设定中解决机器学习问题。它们的重要细节不同,但基本思想共通:服务器协调节点网络,每个节点都有训练数据。每个节点都训练一个本地模型,它是与服务器共享的模型。
让我们更具体地描述联合平均,也许是最简单的联邦学习形式。此算法由Google团队于2016年发布。
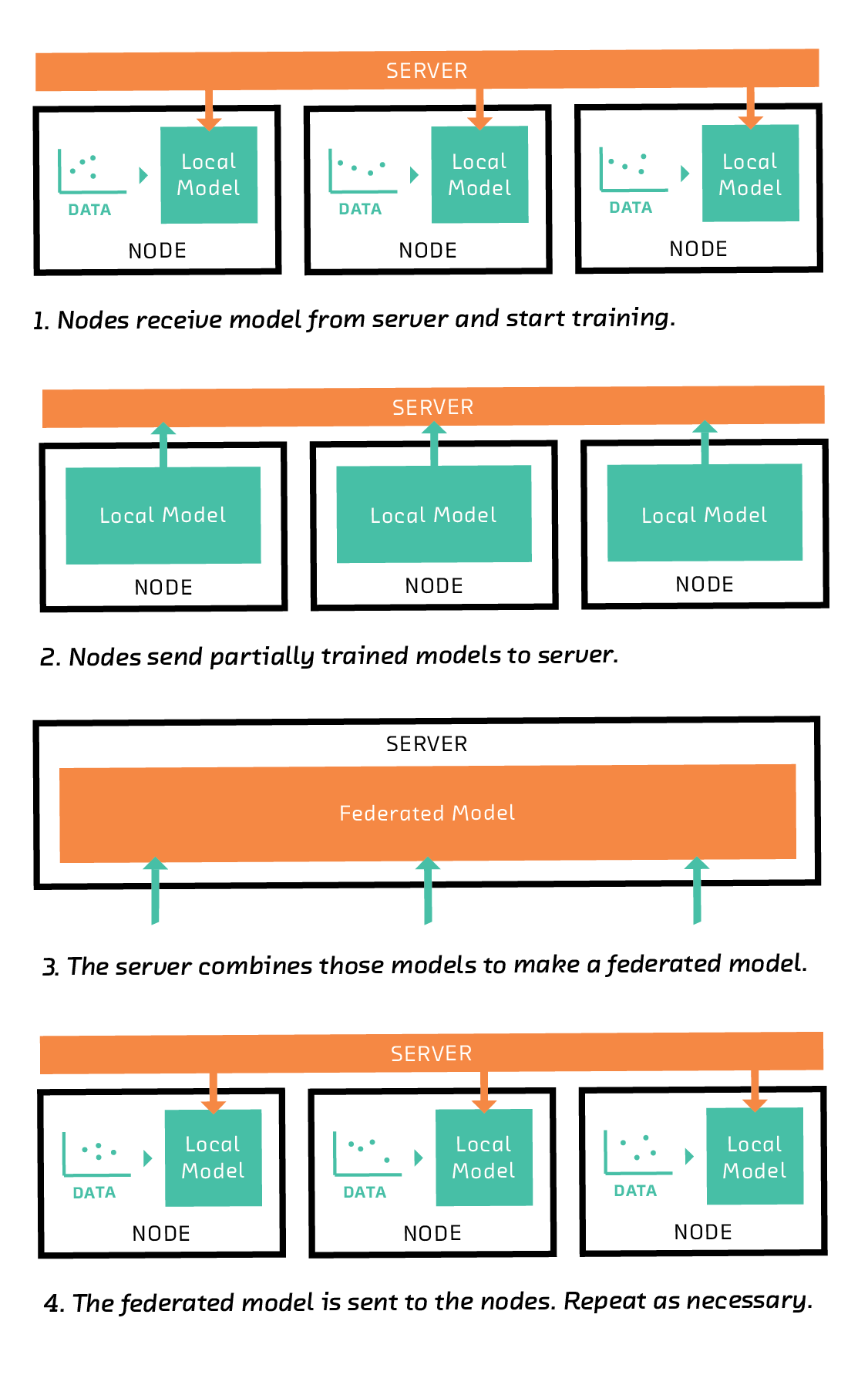
联邦学习图。
首先,节点从服务器接收模型并开始训练。 然后,节点将其部分训练的模型发送到服务器。 服务器获取这些模型并将它们组合在一起以形成联合模型。 该联合模型将发送回节点。 随着不断重复迭代,模型可以在本地进一步训练。
服务器首先向每个节点发送指令以训练特定类型的模型,例如线性模型,支持向量机,或者在深度学习的情况下,一些特定的网络架构。
在接收到该指令时,每个节点在其训练数据的子集上训练模型。通常,训练模型需要算法的多次迭代(例如梯度下降),但是在联邦学习中,节点仅几次迭代训练他们的模型。从这个意义上说,遵循服务器的指令,每个节点的模型都经过部分训练。然后,节点将其部分训练的模型(但不是训练数据)发送回服务器。
服务器组合部分训练的模型以形成联合模型。组合模型的一种方法是取每个参数的平均值,加权相应节点上可用的训练数据量。
然后将组合的联合模型传输回节点,在那里它替换它们的本地模型并用作另一轮训练的起点。经过几轮迭代后,联合模型汇聚到一个良好的全局模型。通过一轮又一轮的训练,节点可以获取新的训练数据。有些节点甚至可能会中途退出,其他节点也可能会加入。
而且至关重要的是,服务器永远不能直接访问训练数据。通过交换模型而不是训练数据,联邦学习有助于确保隐私并最大限度地降低通信成本。
Turbofan Tycoon
我们关于联邦学习报告的原型是Turbofan Tycoon。在其中,您扮演一个想要更好地维护其涡轮风扇发动机工厂的所有者。你的选择是:
- 纠正性维护策略(即等待发动机停止工作)
- 预防性维护策略(即,在固定时间维护发动机,希望在发生故障之前的某个时间)
- 本地预测维护机器学习模型,仅在您的故障发动机数据集上进行训练
联合预测维护机器学习模型,使用联邦学习对80个工厂(包括您的工厂)的集体数据进行训练
剧透警告:最佳策略是联邦学习,相对于替代方案的投资回报率巨大!我们希望您喜欢探索它。
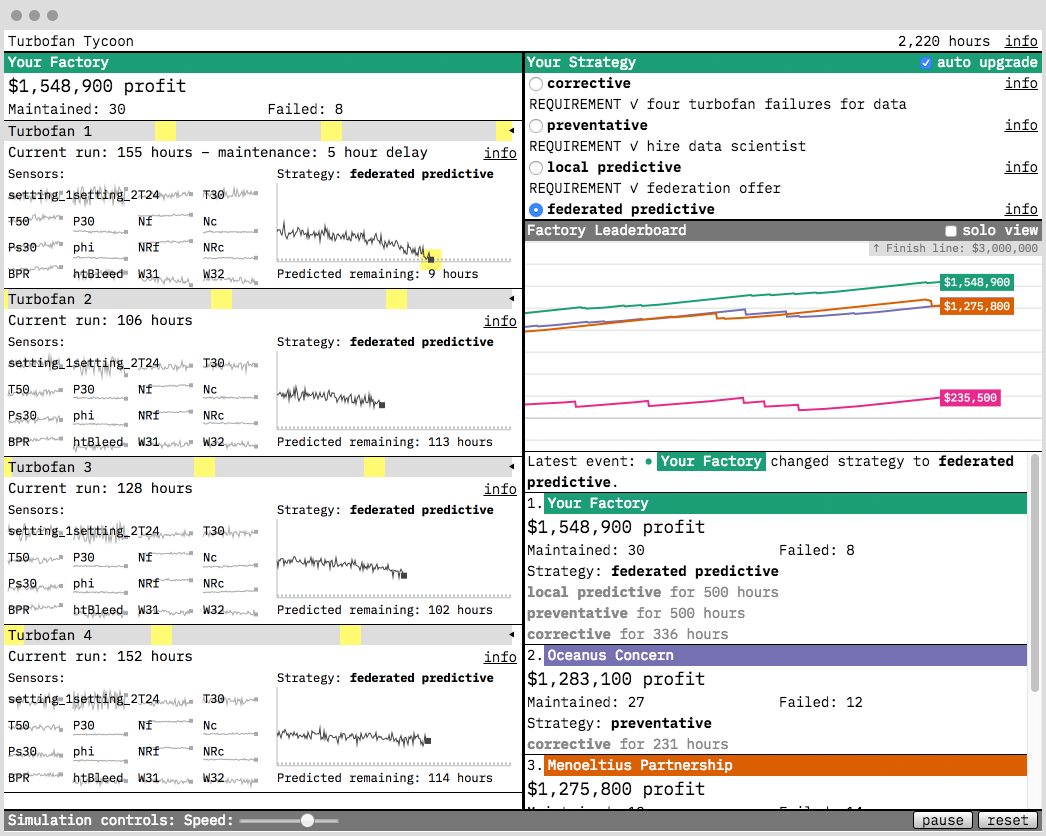
为了训练联合模型,我们使用PyTorch编写了大约100行的代码实现联合平均。该实现是在没有真正的网络通信发生的意义上的联邦学习的模拟。服务器和节点都存在于一台机器上。但是,它是一种算法忠实的实现:服务器和节点仅通过将模型的副本相互发送来进行通信。
这种方法使我们能够快速地对大量节点进行实验,而不会陷入网络问题。尽管简化了,但我们可以重现真实网络面临的许多实际挑战(落后者,连接丢失等)。在每个节点(以及它们的平均值的联合模型)上训练的模型是具有一个隐藏层的简单前馈神经网络。我们在报告中提供了更多细节。
隐私
通过将训练数据保留在其源头,联邦学习将分散机器学习中最明显和最大的安全漏洞。但要明确它并不是最佳解决方案。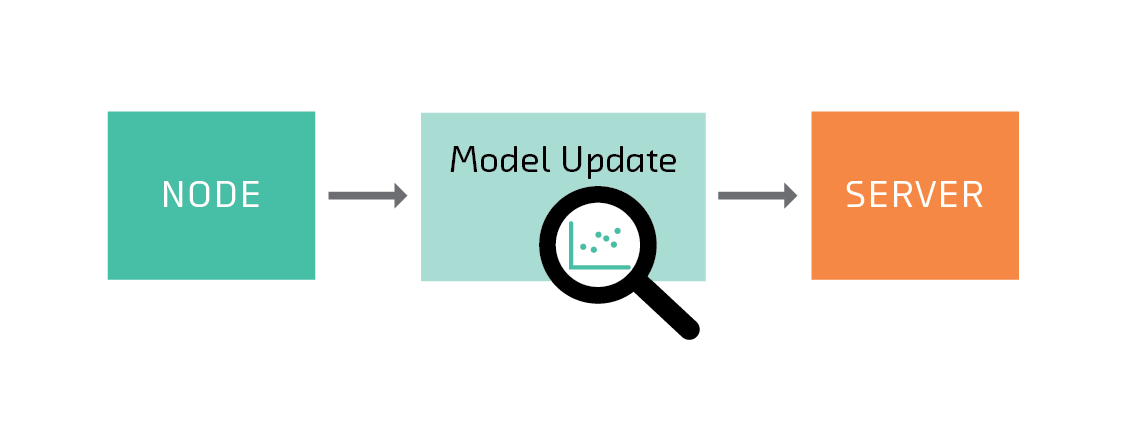
可以从发送到服务器的模型推断节点上的数据信息
这是因为有时可以从模型中推断出有关训练数据的信息。这个问题并非联邦学习所独有 - 任何时候你分享训练模型的预测,就开启了这种可能性。但是,有必要在联邦学习的背景下详细考虑,原因有二:首先,保护隐私是联邦学习的主要目标之一; 第二,通过在(可能不值得信任的)参与者之间分配训练,联邦学习开辟了新的攻击媒介。
推断有关训练数据的信息的最间接方式只需要能够多次查询模型。任何能够通过API间接访问模型的人都可以尝试以这种方式攻击它。这种攻击在联邦学习中不是唯一的(或更危险的)。(例如, Membership Inference Attacks Against Machine Learning Models和 Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures)。
对这种攻击的保护通常是差分隐私。差分隐私是一个庞大的数学领域,其应用远远超出了机器学习。但是在机器学习环境中,差分隐私的应用通常意味着服务器在允许用户查询之前向模型添加噪声。对于现代的,可访问的,面向ML的差分隐私介绍,请查看Privacy and Machine Learning: Two Unexpected Allies。
在联邦学习设定中,服务器和节点相互信任是合理的,这种类型的攻击是比较值得考虑的问题。但是,如果服务器或节点不值得信任,则可能存在其他类型的攻击。

训练数据(左)可以由恶意节点重建(右)(图片来自Briland Hitaj,Giuseppe Ateniese和Fernando Perez-Cruz的“Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning” 文中)。
例如,服务器必须能够直接检查节点的模型以对其进行平均。但是对于某些类型的模型,仅仅一个权重改变的事实就会泄露训练数据中存在特定的特征。例如,假设模型将一个单词作为特征,并且词汇表中的第十个单词是“饺子”。如果节点返回模型的第十个系数已更改的模型,则服务器或中间人可能能够推断该节点上的训练数据中存在“饺子”一词。
在实践中,这种攻击更难以对付现代(和更复杂)的模型。可以通过差分隐私(更复杂的)或安全聚合来减轻风险。差分隐私方法使每个节点在与服务器共享之前向其模型添加噪声(例如, Communication-Efficient and Differentially-Private Distributed SGD)安全聚合协议使服务器可以使用加密的副本计算节点模型的平均值,它并没有解密的能力。这两种方法都增加了通信和计算开销,但这可能是在高度敏感的环境中值得做出的权衡。
个性化
在“常规”联邦学习中,服务器的目标是使用每个节点上的数据来训练单个全局模型,但是在节点计划应用模型的情况下(不仅仅是对其自己创建的模型有贡献),它通常会更多关注的是,本地模型捕获其数据中的模式比任何其他节点的数据更加准确。例如,如果我是一个正在训练模型的网络中的节点,该模型将帮助编写更有可能收到回复的电子邮件,我更关心该模型对我的作用而不是对其他人有效。
如果全局模型具有适当灵活的体系结构并且在许多良好的训练数据上进行训练,那么它可能比在单个节点上训练的任何本地模型更好,因为它能够捕获许多特性并推广到新模式。但有时在实践中,用户的目标(本地性能)可能与服务器的(全局性能)冲突。
研究个性化的目标就是解决这种倾向情况。在联合多任务学习中,Virginia Smith和合作者将个性化框架转化为一个多任务问题,其中每个用户的模型都是一个任务,但是存在一个与任务相关的结构。
结论
联邦学习使机器学习在世界上最受监管,最具竞争力和最有利可图的行业中应用变得更容易,更安全,更便捷。它是当前非常活跃的研究领域,在隐私,安全,个性化和其他领域也存在很多开放性问题。