Ansible Playbooks for Apache Kafka in production
Junyangz
4月 29, 2019
前言
参考了confluentinc/cp-ansibleplaybook批量安装部署Apache Kafka 2.2.0. 已在Github上开源
注:集群的zookeeper集群已通过Cloudera Manager安装了,所以不包括Zookeeper的安装部分
Apache Kafka & Systemd
Requirements
- Ansible setup on your terminal
- rhel7/CentOS7
- Zookeeper cluster
- Ansible playbook(repo)
- offline dist(Apacher Kafka)
Source tree
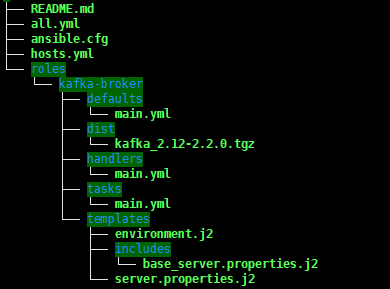
注:仓库里不含Kafka发行包
kafka_2.12-2.2.0.tgz,需要自行下载并放置在上图的位置中
hosts.yml里列出所有的主机角色,包括Zookeeper和Kafka brokerall.yml里列出对位于broker分组中的主机执行task任务
理解和使用
运行
#ansible-playbook -C all.yml #运行之前可以先检查下,检查没问题后再运行
ansible-playbook -i hosts.yml all.yml
roles/kafka-broker/defaults/main.yml
配置安装过程中的所需变量即Zookeeper端口,Kafka broker配置,Systemd等相关内容
roles/kafka-broker/handlers/main.yml
配置完Systemd服务后执行daemon-reload并重启Kafka broker
roles/kafka-broker/tasks/main.yml
任务执行流,创建Kafka用户及用户组,创建Kafka数据目录,分发Kafka发行包,更改权限,拷贝broker配置文件并修改,创建systemd文件并启动Kafka
roles/kafka-broker/templates/
该文件夹下放置了broker的配置文件和Systemd文件,执行的时候将defaults设定的变量写入到文件中
默认配置文件参考了confluent Kafka的配置,请自行修改成自己所需的配置。
部署后可以使用 journalctl -xefu kafka检查Kafka的运行日志,部署目录/opt/apps/kafka/logs下也有相应的日志文件,此外还可以在Syslog中自行配置Identifier=kafka的日志处理。例如传输到各种监控程序中。